Who needs this
- ML engineers shipping models to staging and production clusters
- LLM teams running on-prem inference with governance requirements
- Tech leads bridging data science notebooks and platform standards
Tech team · AI & ML engineering
Model builders need GPU visibility, sane deploy paths, and the same cluster context as platform—not a separate “AI portal” that drifts from production. FusioNative keeps LLM deploy wizards, inference KPIs, and pod-level workloads in one navigation model.
LLM, GPU, and Kubernetes workloads in one engineering control plane
Design, deploy, and observe LLMs and training workloads on Kubernetes with GPU metrics beside the pods they run on.
Real screens—how and why each view matters for your sector.
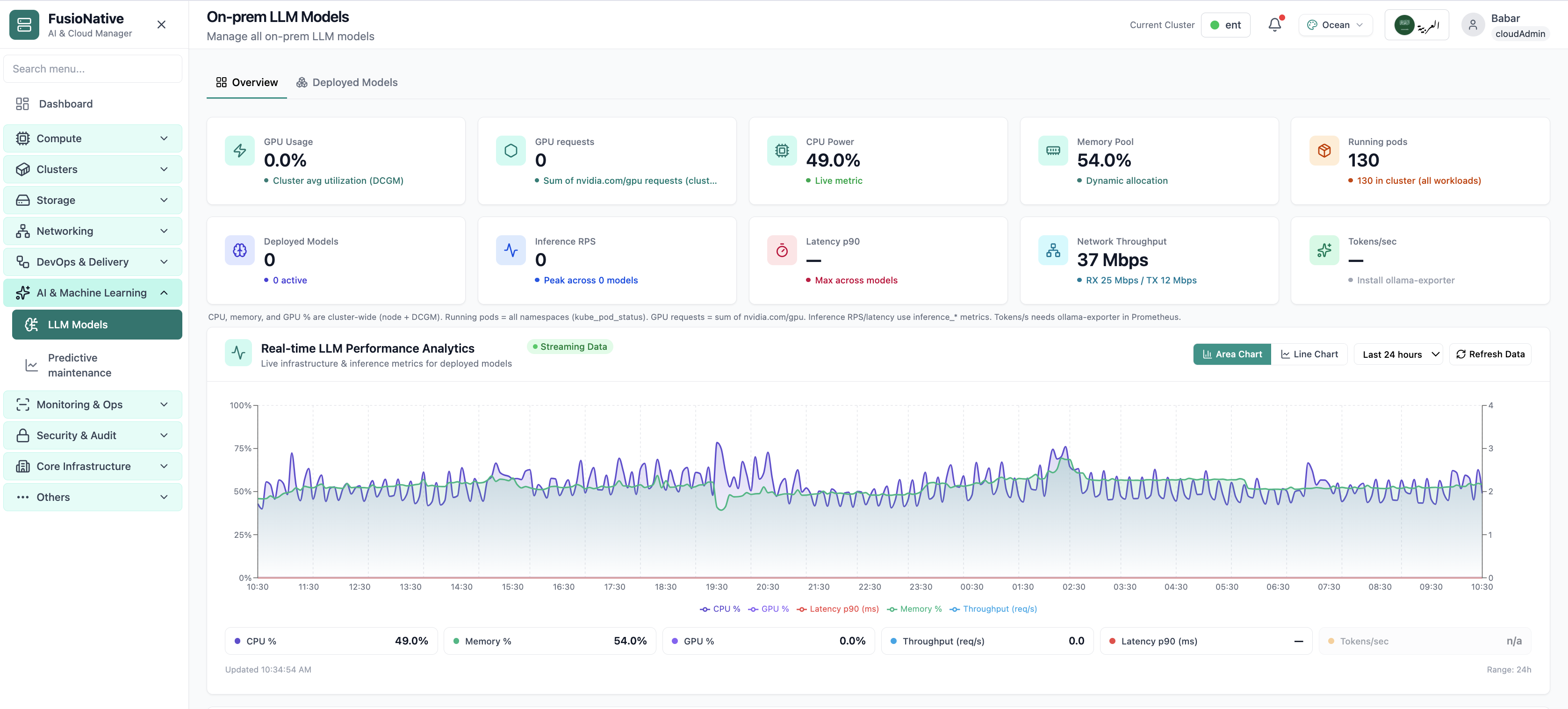
Model KPIs and GPU signals on one overview—where ML leads start stand-ups.
Click to zoom and pan the screenshot.
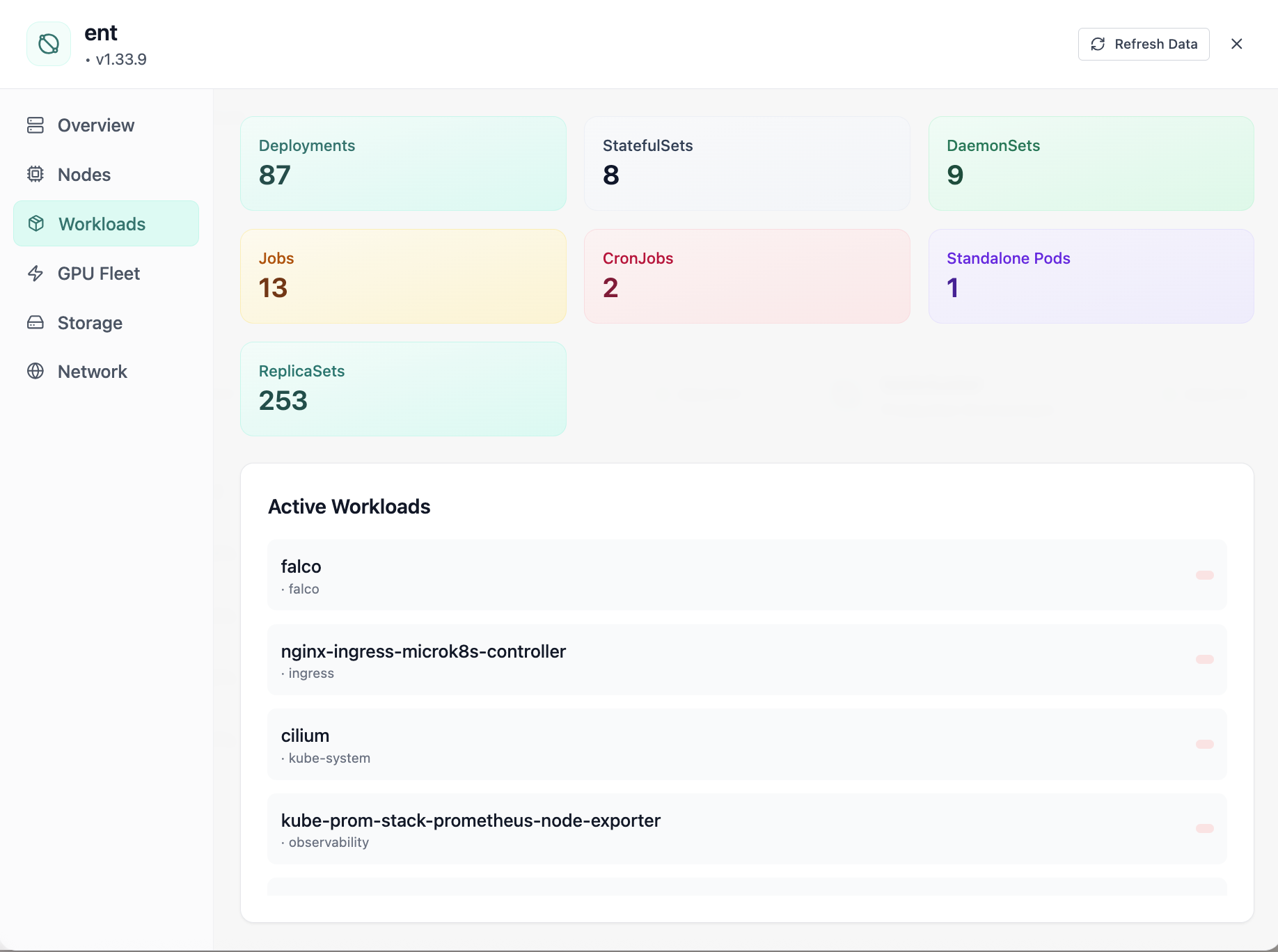
Deployments, StatefulSets, and GPU pods in one inventory—tie models to the objects platform actually runs.
Click to zoom and pan the screenshot.
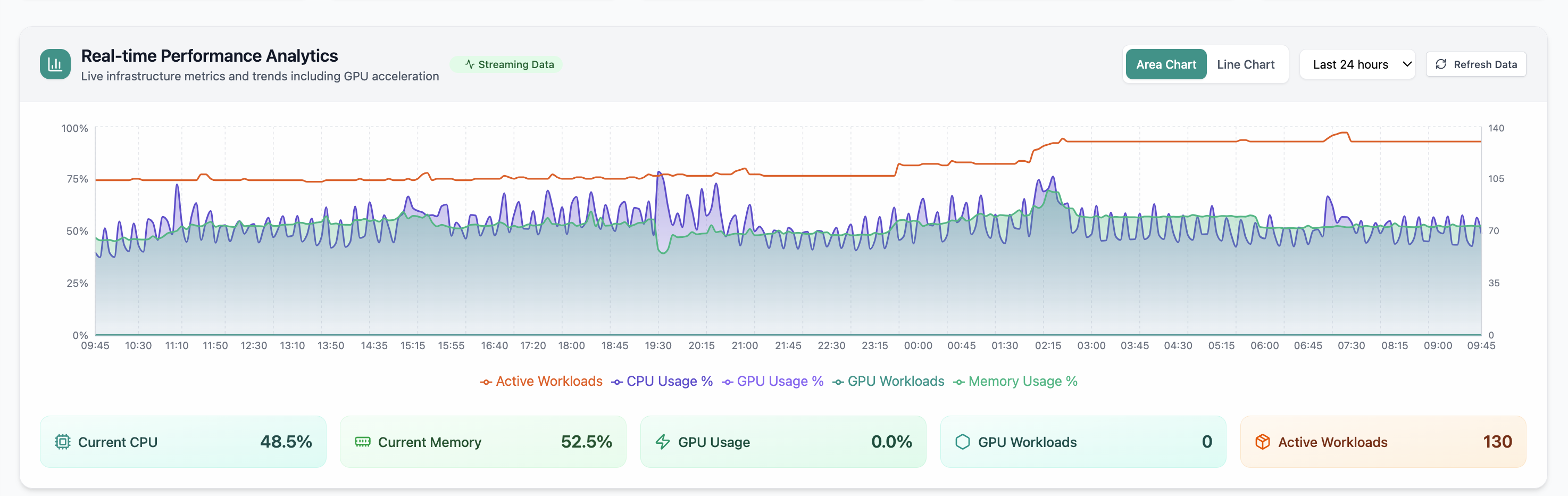
24h CPU, memory, and GPU trends—spot training or inference spikes before they exhaust the pool.
Click to zoom and pan the screenshot.