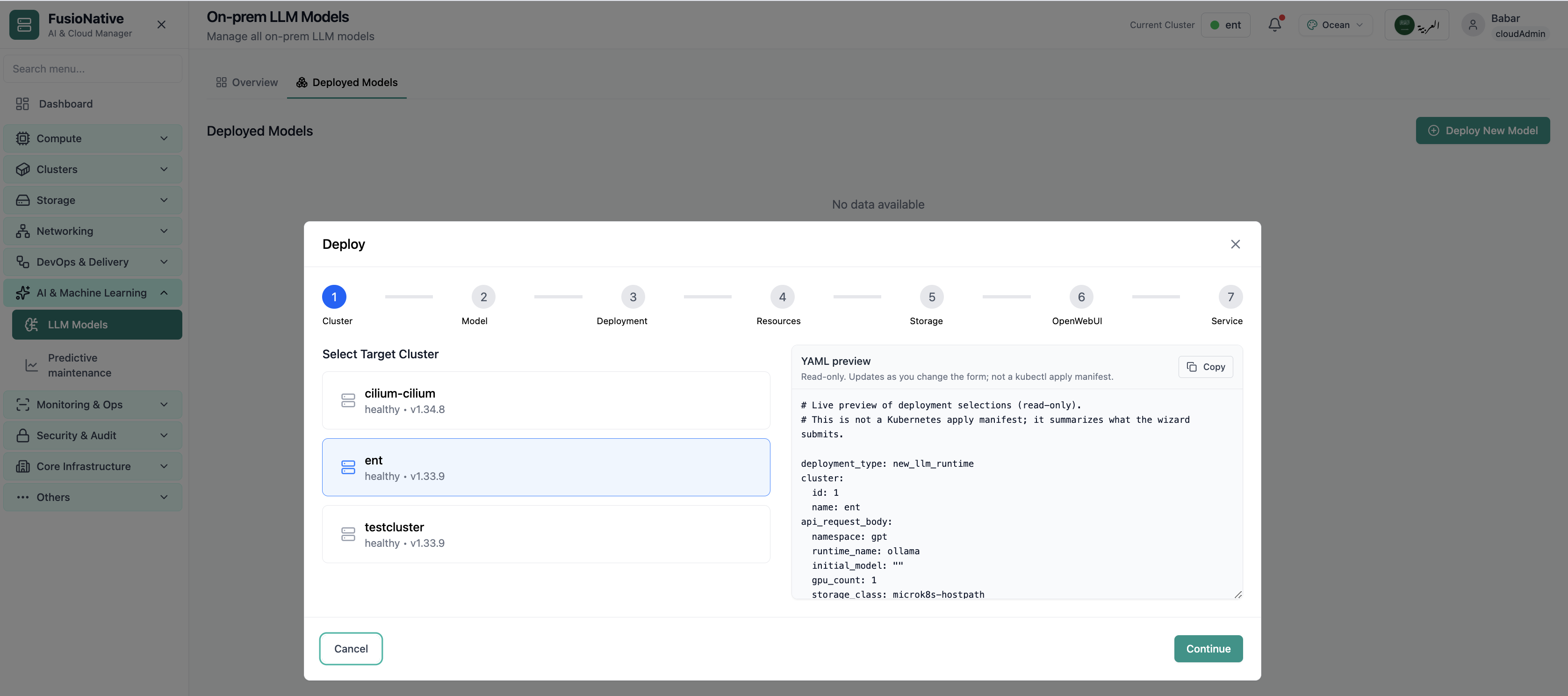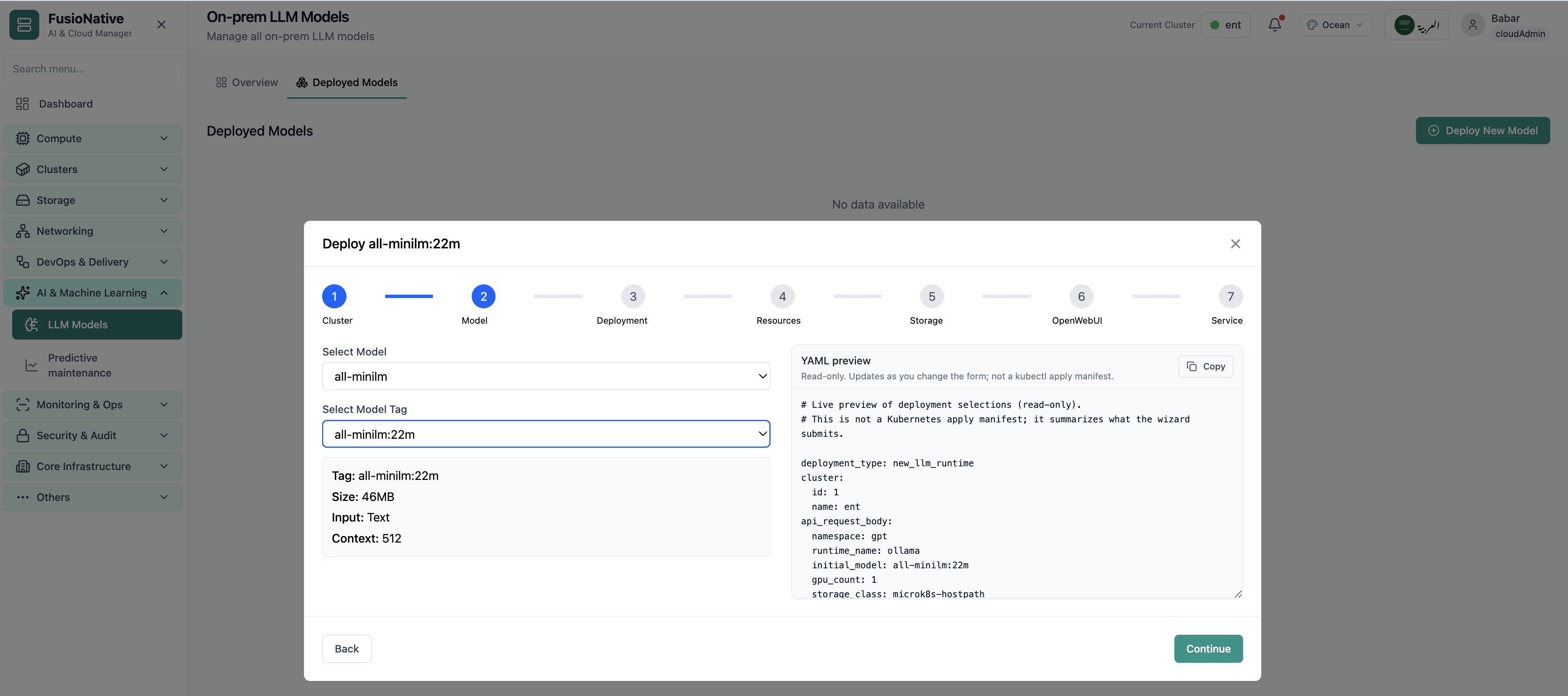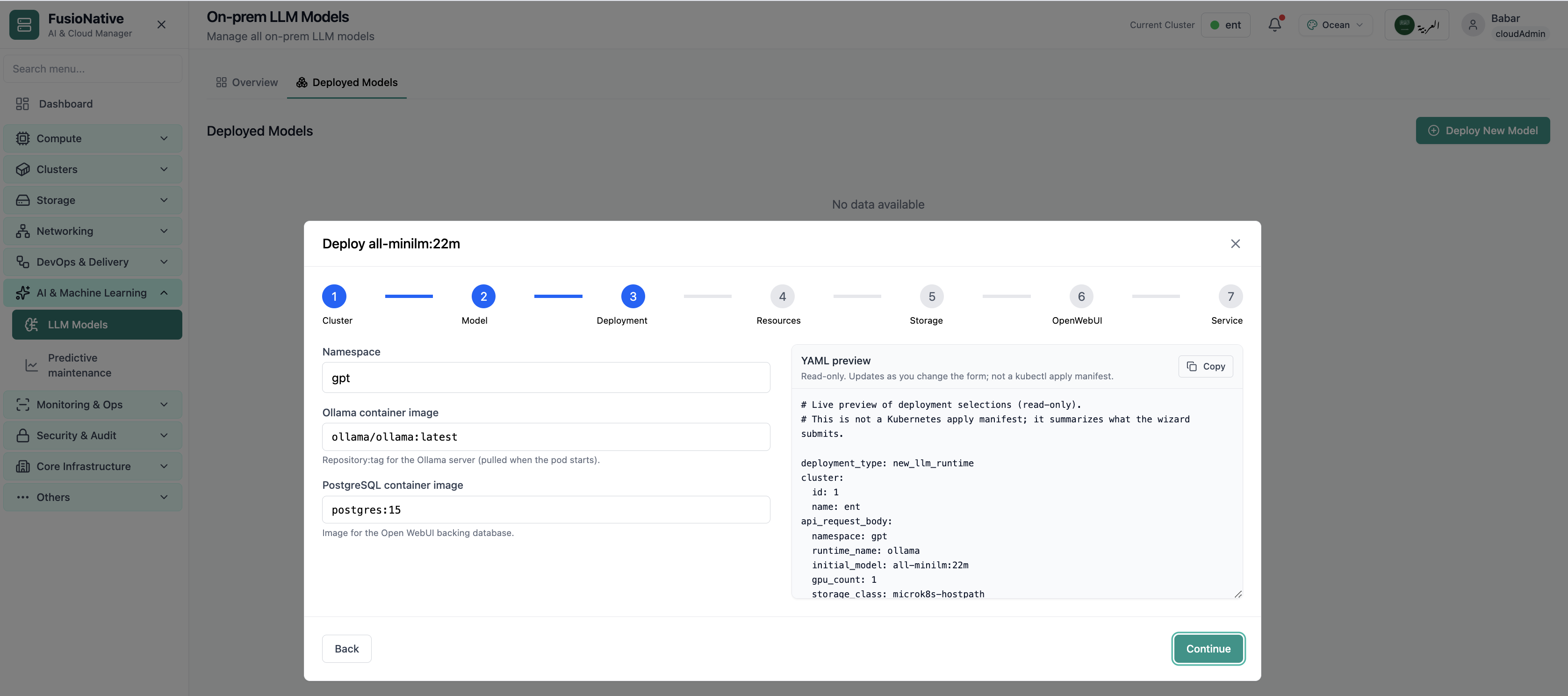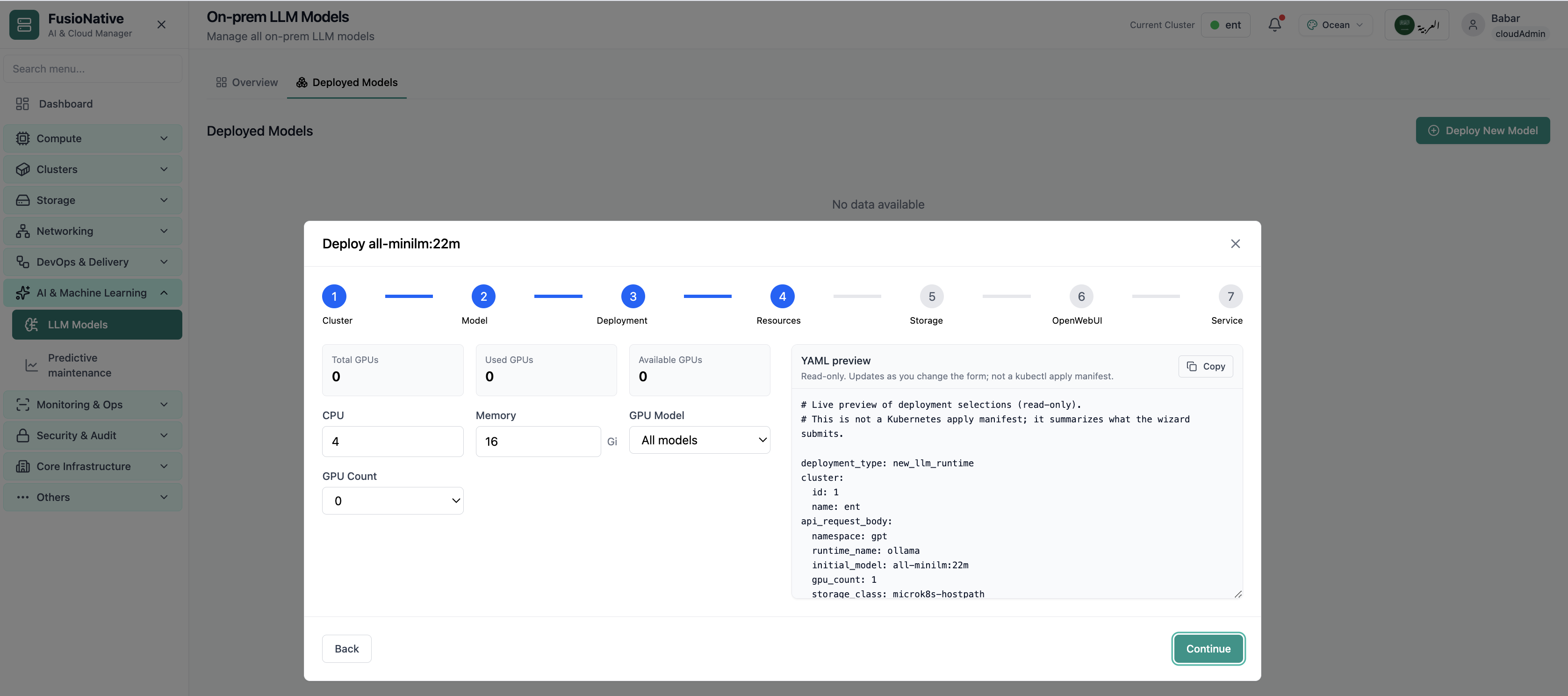
LLM Overview
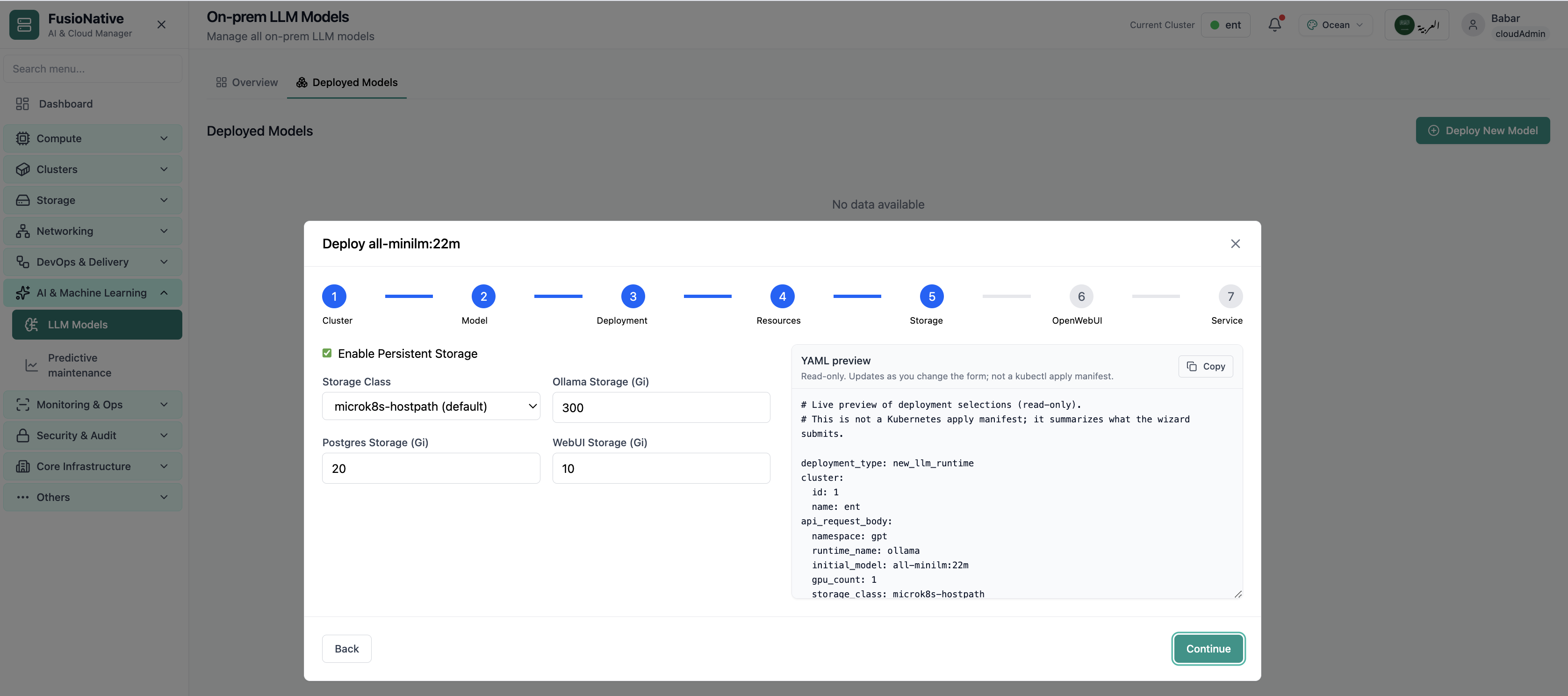
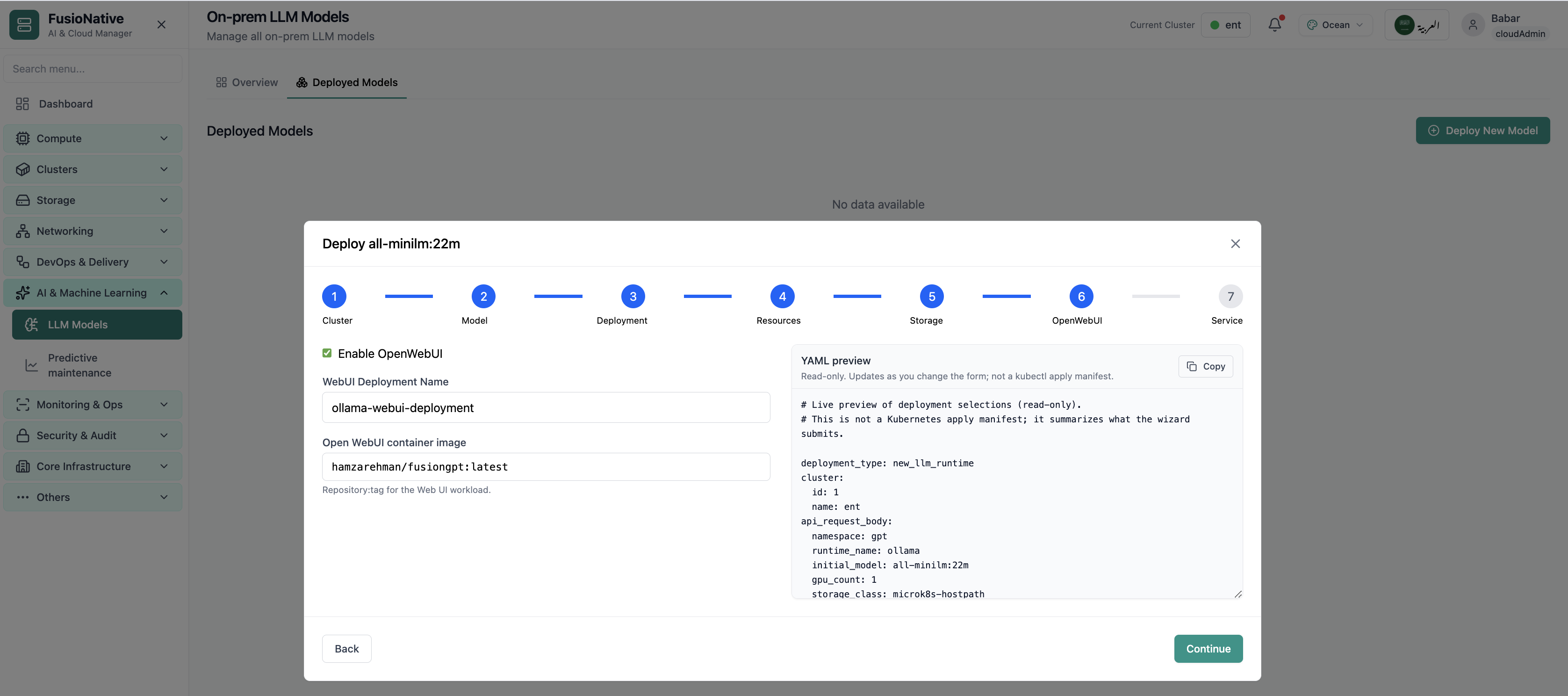
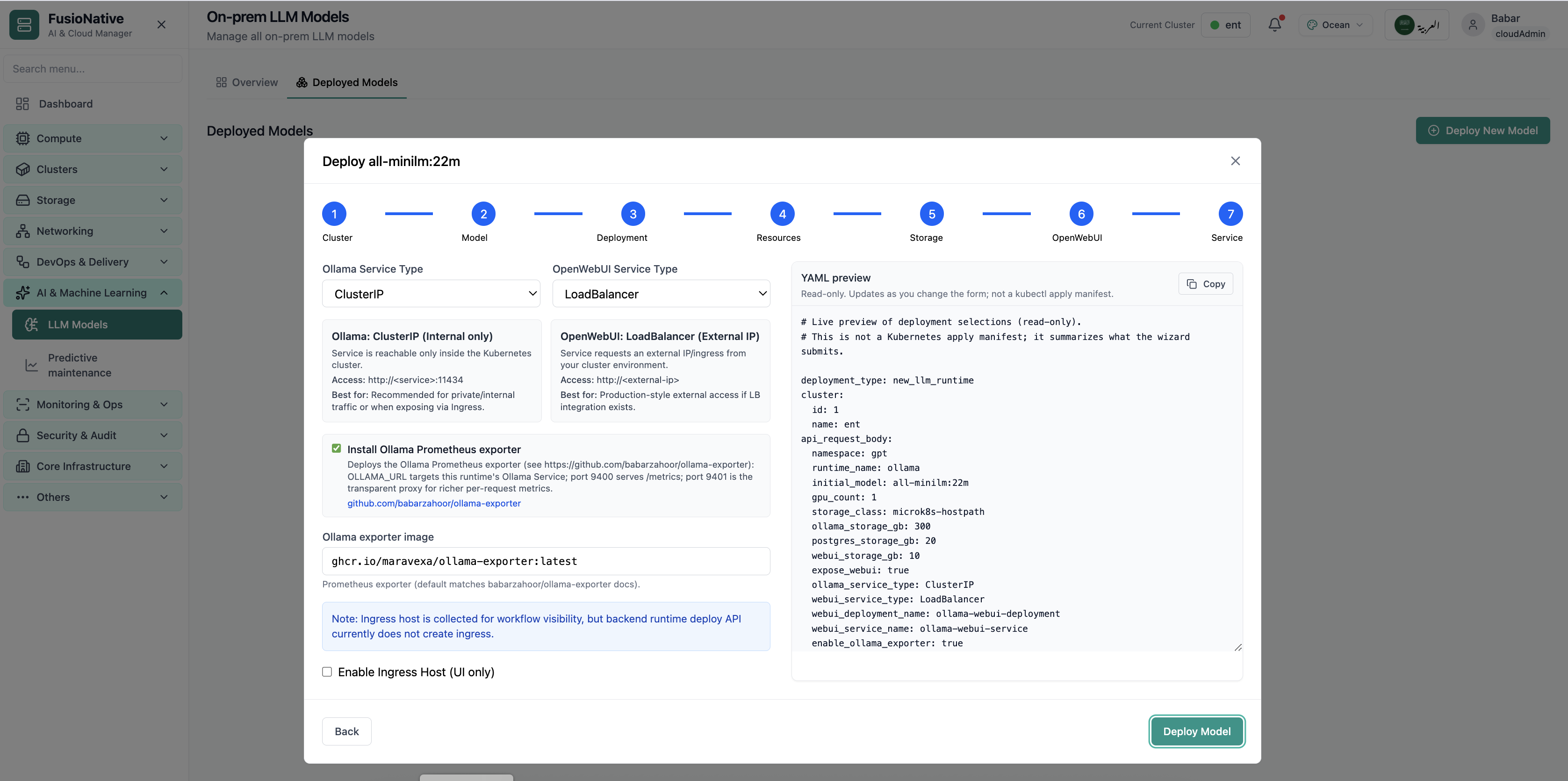
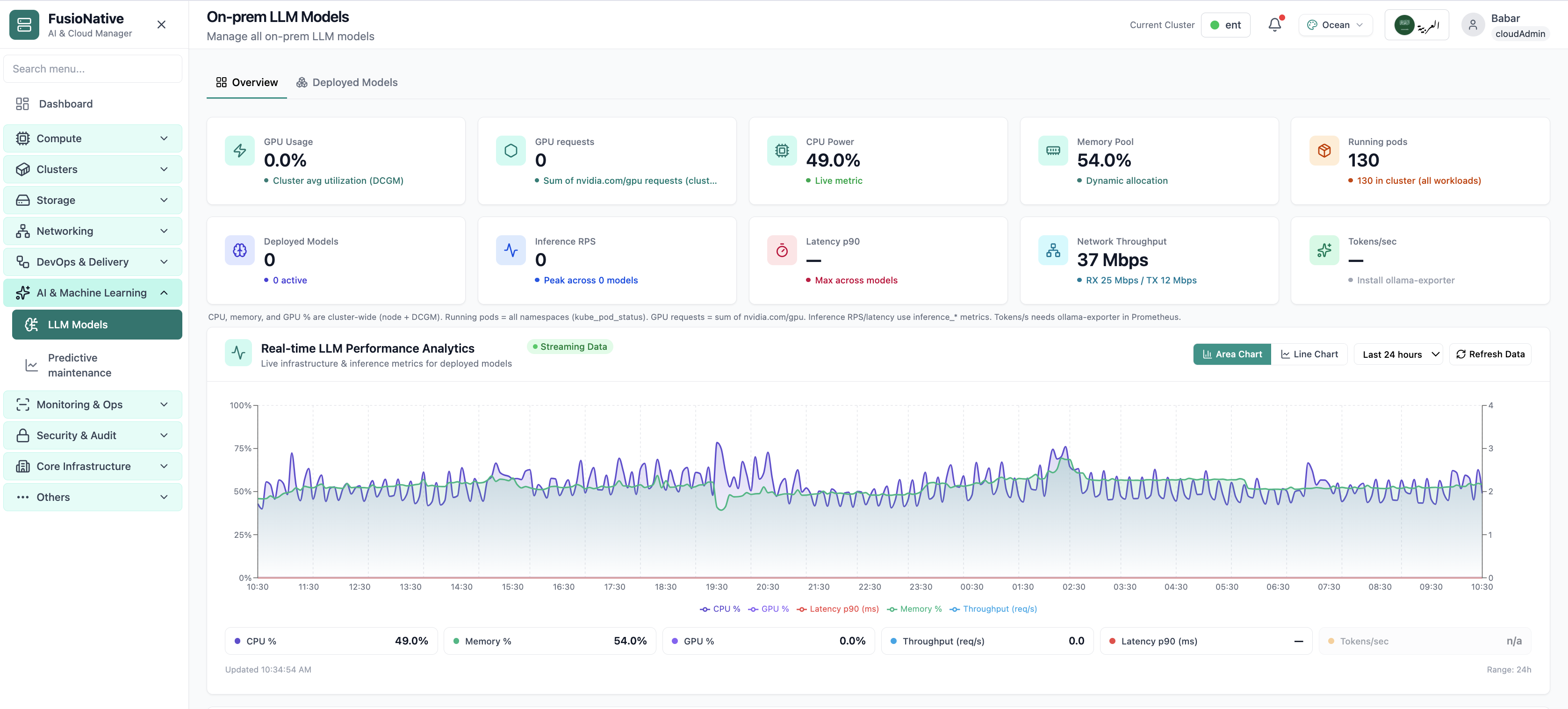
Your starting point for on-prem LLM models: KPI cards and charts summarize fleet health, including on-prem llm models overview with gpu and inference metrics. Spot drift early, then drill into the tab that explains the root cause.
- GPU and inference signals stay beside Kubernetes metrics
- Charts link utilization to time so you spot spikes quickly
- One click into deeper tabs when something looks off
Click the screenshot to open full size, zoom, and pan.