Who needs this
- MLOps engineers owning the path from registry to production
- Inference platform teams standardizing deploy templates
- Reliability partners pairing models with SLO dashboards
Tech team · MLOps
MLOps sits between ML code and platform reality. FusioNative gives you a repeatable deploy path for models, GPU allocation you can defend in review, and monitoring that speaks both inference and infrastructure.
Deploy and monitor models on Kubernetes with guardrails
Take models from artifact to monitored production services with wizard-driven deploys and fleet-grade observability.
Real screens—how and why each view matters for your sector.
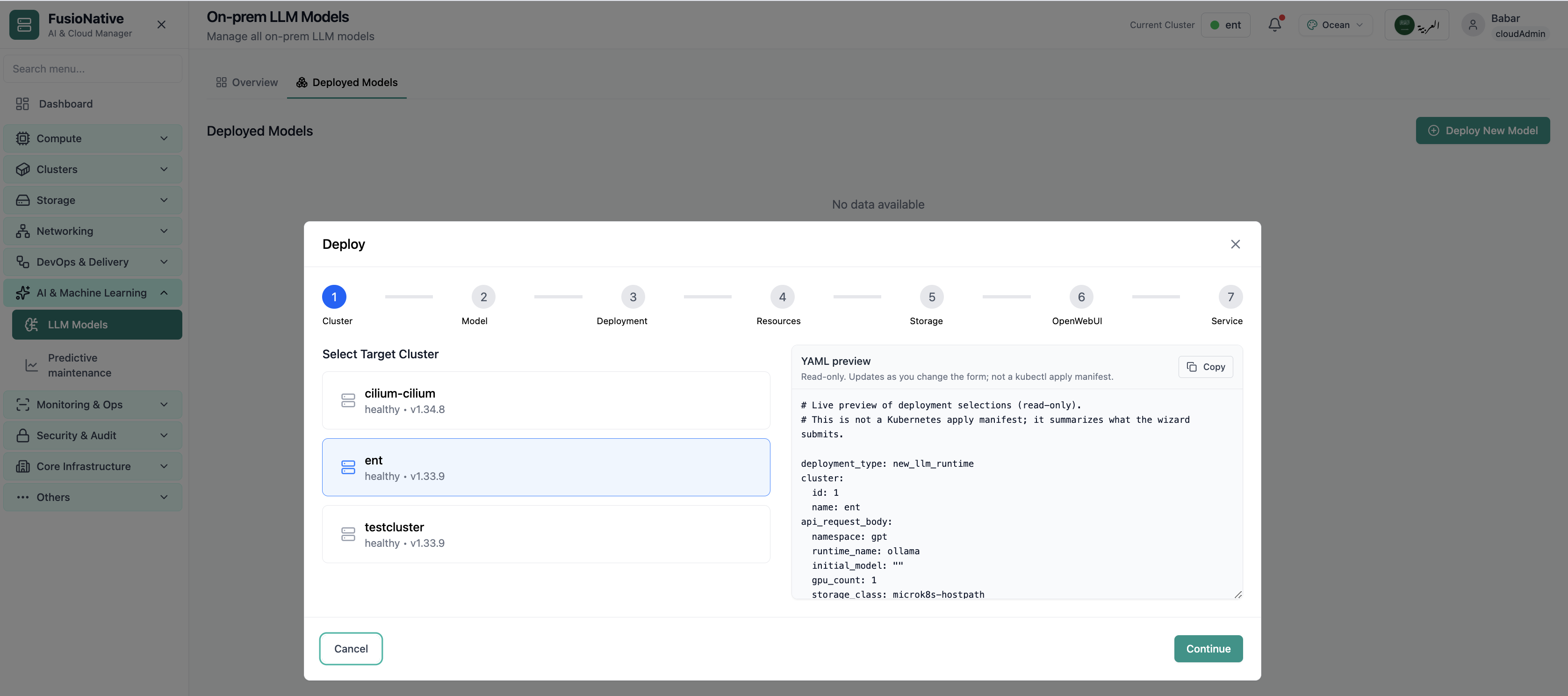
First wizard step—anchor the model to the right cluster and policy boundary.
Click to zoom and pan the screenshot.
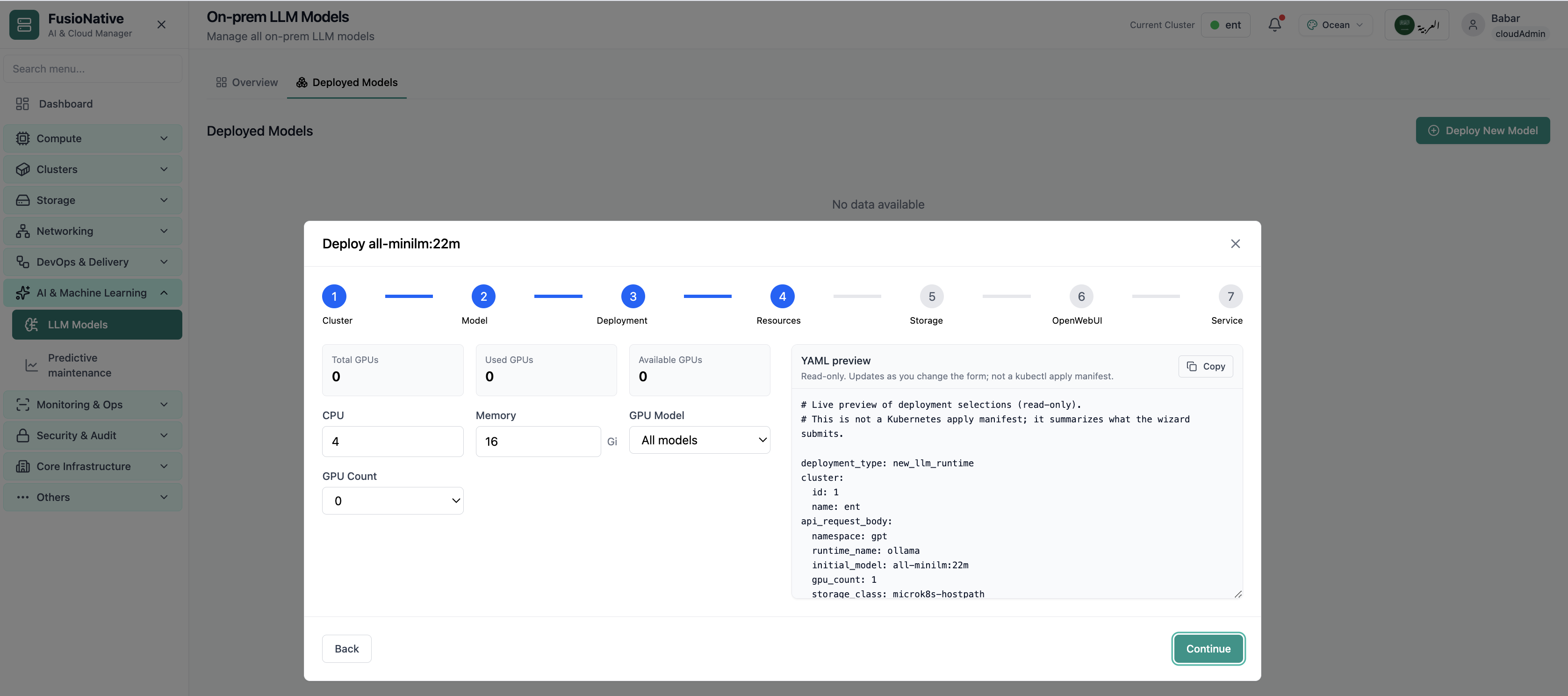
GPU and CPU allocation step—align requests with real pool headroom.
Click to zoom and pan the screenshot.
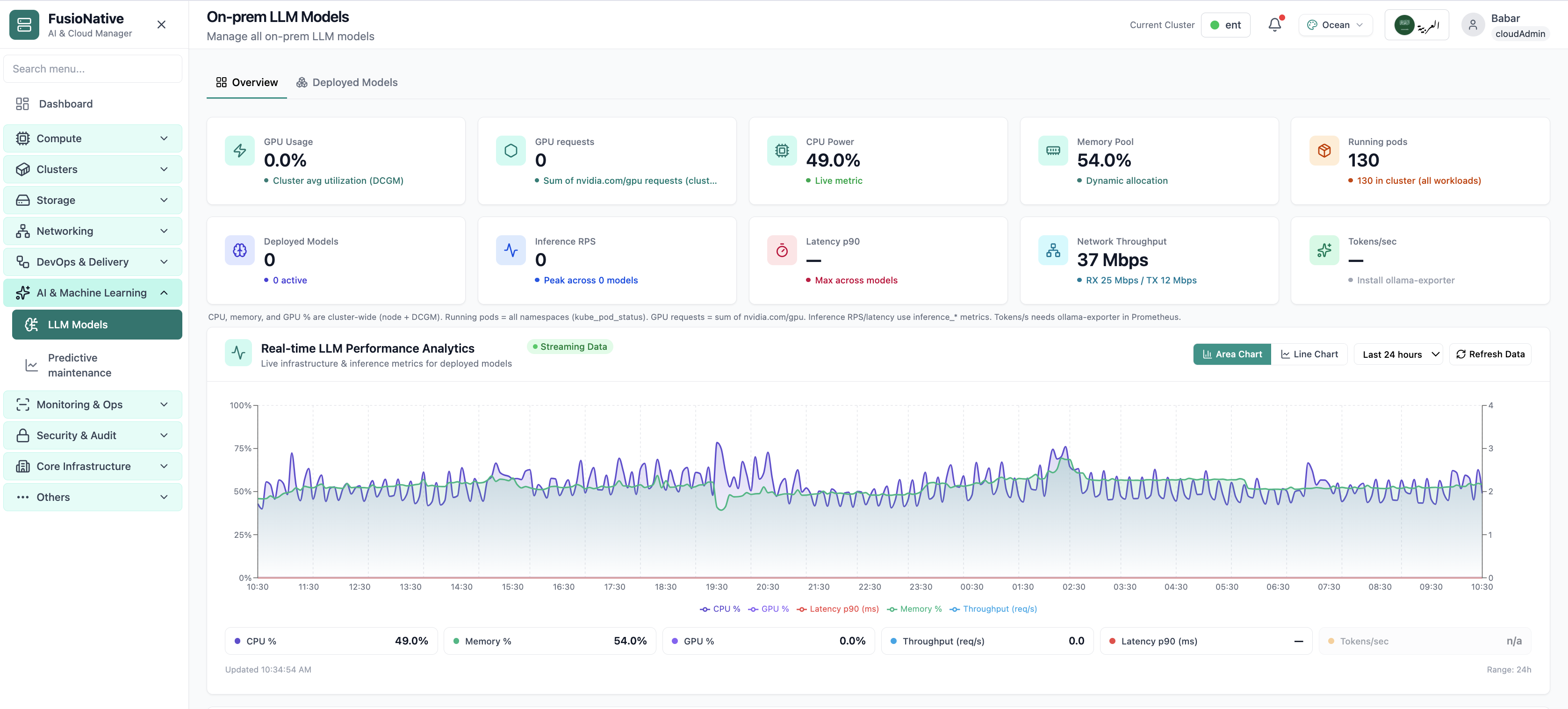
Post-deploy KPIs—operations view after go-live.
Click to zoom and pan the screenshot.